
Overview

I attended ScaledML 2020 earlier this year. Unlike NeurIPS, ICML, [insert your favorite research-flavored ML conference here], ScaledML is primarily industry-focused. That being said, the quality bar of the presentations is really high. They are also engineering-focused; as a result, I absorbed more relevant ideas attending ScaledML for 1 day than I did from attending NeurIPS for 1 week.
I thought I would share the notes that I took during the conference. Talks that I found particularly interesting are starred (*). Bear in mind that these are stream-of-consciousness notes and have been very minimally edited. For the fully polished presentations, I recommend checking out the ScaledML 2020 videos. As I only attended Day 1/2, only half of the presentations are covered here.
- Turning ML Research into Products for Industry - Reza Zadeh & Matroid Team
- Machine Learning at Google Scale - Megan Kocholia
- AI at Tesla - Andrej Karpathy *
- Large Scale Generative Models and RL - Ilya Sutskever *
- AI and The Future of Humanity - Oren Etzioni
- Apache Arrow: Present and Future - Wes McKinney (creator of Pandas), Ursa Labs *
- Human-centric Approach to ML Infrastructure - Savin Goyal, Netflix *
- Shipping AI Products - Panel Discussion
Turning ML Research into Products for Industry - Reza Zadeh & Matroid Team
tl;dr When applying ML to products we need to think about what accuracy is adequate for the use case. Use cases that can tolerate error are a better fit for ML then use cases that can’t. Reza also did a cool demo of his company’s Matroid product (GDocs for annotation, chained detectors, confusion detection, etc). Would be awesome to build something like this for NLP.
- Why has it been so hard to put ML from academia into product?
- What is adequate accuracy for your use case?
- Even at 99% accuracy, mistakes can happen
- Accuracy alone is not that meaningful, unless you ground it in something
- Not even counting traditional software mistakes, bugs, etc. in this talk
- Stakes of situation determine what accuracy you need.
- Recommendation systems are low stakes, not a big deal if Netflix recommends the wrong movie. Most success with ML has been in low stakes areas so far.
- Other end: Self-driving cars have been “5 years away” for the past 15 years
- So many edge cases that must be handled. Unclear when we will have it, though Andrej might have some hints :)
- Even at 99% accuracy, mistakes can happen
- What is adequate accuracy for your use case?
- Examples in NLP and CV:
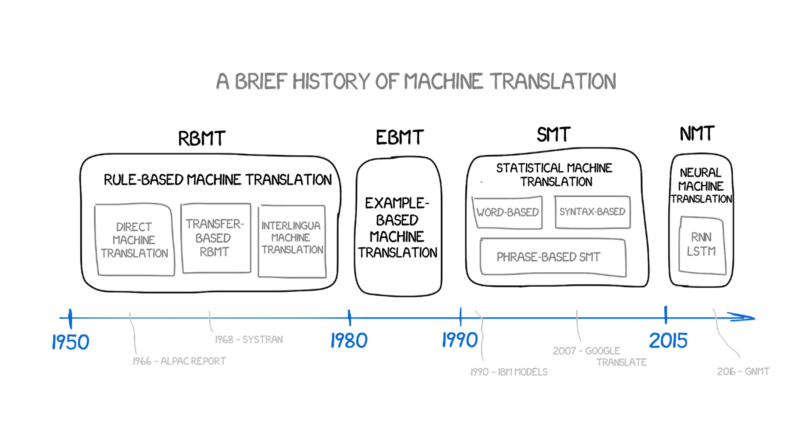
- Machine translation and speech recognition
- People forget there were 5 decades of research before it finally became useful!
- RBMT > EBMT > SMT > NMT
- Speech recognition only started working in the past 6 - 7 years.
- New speech products
- Keyword searches
- Voice searches
- New speech products
- People don’t think long enough about how long it took to work
- Machine translation and speech recognition
- Computer vision is finally getting to a point where we can productize it.
- Product use cases of CV (Reza had ~10 examples of these):
- Restaurant kitchen
- Challenges: Hard to enforce rules
- Ensure employees must wash their hands
- Ensure no meat on vegetarian cutting board
- However if you do this right, adequate accuracy is very low
- Challenges: Hard to enforce rules
- Retail analytics
- Challenges:
- Determine footprint heat maps to determine popularity of shelves
- Alert to suspicious employee behavior with freebies
- Implement various metrics about time spent by customers
- Challenges:
- Roofing manufacturing
- On nigh speed manufacturing conveyor belt, identify anomalies early, before defects make it down production pipeline
- Stop the line if there is a mistake
- The cost of false positive is low (stopping the line takes 30s), cost of false negative is high
- If you find an anomaly and fix it, then it saves the company a lot of $
- Restaurant kitchen
- Summary of use case
- Manufacturing
- Medical Imaging Diagnostic Aid (more discussion on this later)
- Weaponry :(
- Product use cases of CV (Reza had ~10 examples of these):
- Use cases that can tolerate error are often better candidates for ML
- In CV right now we’er OK at nouns, verbs are coming and ready for products at much smaller rate
- There are millions of improvements in noun
- Verbs get better in thousands per yer
- Key for Product Managers
- Develop rigorous understanding of how far from AA (adequate accuracy) the team is
- Not good about modeling rate of change of accuracy in addition to revenue
- Rate change matters
- CLSVRC top-5 error on ImageNet
- In CV right now we’er OK at nouns, verbs are coming and ready for products at much smaller rate
- Key takeaway
- Thoroughly understand adequate accuracy!
- Cloud or on-premise Kubernetes
- “Live in the Product”
- Check out the matroid dashboard!
- Takes 5PB and index + query
- Matroid Demo
- Collaborate on the annotation library, invite others to annotate with you (like GDocs)
- You can download the data if needed as well
- Product is point-and-click
- Cloud managed locations & on-prem locations
- Software considerations you need to make to ML systems deployable
- Connect thousands of ONVIF Devices
- Detecting cars in Bloomberg videos
- Cutting edge detector interpretability
- PCA projection shows you where the model is confused
- Complex things possible
- Combine and chain detectors
- Sliding detectors
- Improve on existing detectors
- Model compression
- Parameter pruning, sharing, quantization
- Low-rank factorization
- Knowledge distillation
- Cutting edge detector interpretability
- Can compress & optimize for target edge AI chip, under a week-long SLA
- Collaborate on the annotation library, invite others to annotate with you (like GDocs)
- Medical Diagnostics
- Diagnosing Glaucoma from OCT Scans
- Radiologists are NOT going to be out of a job anytime soon.
- Better than human detection of glaucoma from OCT scans
- More likely reality: augment the powers of doctors
- New augmentation + cropping strategy proves model uses ares currently ignored by doctors
- arxiv.org/abs/1910.06302
- Human doctor vs. a matroid model
- Diagnosing Glaucoma from OCT Scans
Using a small set of labeled data, how to take advantage of unlabeled data?
- It’s not actually that hard to get labeled data
- Unsupervised learning – that is not quite ready yet. Nothing beats supervised learning yet.
- Focused on getting people the best situation.
Machine Learning at Google Scale - Megan Kocholia
tl;dr Megan went over Google’s contributions in CV and NLP (esp. BERT, XLNet). Google cloud has a lot of cool offerings. Outside of models there is also a profound increase in requirements for compute. To support this Google is offering Cloud TPU. Data engineering service is also coming soon (https://cloudonair.withgoogle.com/events/data-eng)
- Where Google uses ML
- Images and Videos
- Text, Speech, Audio
- 3 big advances changed everything
- Diverse datasets
- OpenImage - 9 million images
- Data privacy and data security are big things as well
- Advances in ML techniques in language understanding
- RNNs & Transformers (2016 - 2017)
- BERT (2018)
- XLNet (2019)
- Generalized autoregressive pretraining for language understanding
- Outperformed BERT
- Diverse datasets
- The challenge: profound increase in compute requirements
- Datasets need lot of compute
- Hundreds of thousands, millions of labels
- High-quality labelset
- Increases in model accuracy require much more compute
- Accelerators, TPUs
- TPUv2: Google’s first Tensor Processing Unit (TPU)
- Cloud TPU v2 Pod: now GA
- g.co/cloudtpu
- Rapid progress
- TPU v1
- TPU v2
- TPU v3
- Cloud TPU Pod
- 11.5 petaflops -> 100! petaflops
- Scalable
- As soon as you fix one bottleneck new ones show up
- Datasets need lot of compute
AI at Tesla - Andrej Karpathy *
tl;dr Tesla Autopilot is all driven by Computer Vision, there is no need for Lidar at all! Why has self-driving cars taken so long? Mostly because of hard edge cases that must be handled. Tesla has the world’s largest collection of weird stop signs. “Operation Vacation” is similar to AutoNLU in that you run unit tests, if they fail, collect more training data until the model gets it right.
- Averting Collisions
- 10-100s of Pedestrain AEBs
- Tesla Autopilot
- Full self-driving
- What is taking so long? Why are we so late?
- Waymo 10 years ago vs. Tesla
- What’s different
- Use entirely vision-based approach (no Lidar)!
- No HD maps
- Harder problem, but once we have it, we can deploy it to millions of cars
- So many edge cases
- Going through the long tail and sourcing for examples of failure
- Data Engine
- Process by which we apply active learning – find examples where the model is failing and label those.
- This is the bread-and-butter of how to make the system work
- Put just as much work as testing as we do in training
- Built out complicated unit tests that cover every case
- This is very similar to slice-based testing!
- Modeling
- HydraNet
- 48 networks
- 1,000 distinct prdictions (# of output tensors)
- None of these tensors can regress and all of them must improve over time
- 70,000 GPU hours
- All of this is maintained by a dozen people
- Operation Vacation
- new task —–> (latency) All unit tests pass. It runs in the car, works well.
- HydraNet
- Neural Networks for FSD
- Software is eating the world
- Software 2.0 is eating Software 1.0
- Code is the outcome of an optimization
- “Compiler” takes dataset and spits out the model
- You can engulf more and more of the Software 1.0 stack.
-
Fusion layer -> module -> BEV Net
Temporal
- Software 2.0 is eating Software 1.0
- Per-pixel depths from vision, without Lidar
- Predict the depth, then cast out into 3D
- When people are driving, they are already teaching you how to drive the car
- With self-supervised learning, we could speed up the rate at which we collect labeled data. However, this is still a long-term research direction rather than a short-term reality.
- Software is eating the world
- tesla.com/autopilotAI
- Team is tiny, only dozens of people!
Large Scale Generative Models and RL - Ilya Sutskever *
tl;dr Generative models and RL can lead to cool and often even human-interpretable results (in the hide and seek game below, agents get progressively smarter). The models are not only more powerful than people thought but also creative. Main criticism of self-learning / RL is that it cannot be applied to the real world, but that might be changing with models like Dactyl which use “Automatic Domain Randomization” to increase robustness.
- OpenAI Five
- Play the game DOTA2
- DOTA: a grand challenge (but not any more) - Paper is out!
- More similar to the real word than other games
- We beat the world champions 2-0 in a best of-three live match
- Very large scale deep RL
- 45,000 years of gameplay
- Self play – no data from human players
- Where is the science?
- Learning is that it is a lot more powerful than people thought
- Learning is Human-Interpretable
- Learning gets stuck for human-enterable reasons
- Human-interpretable reward shaping gets it unstuck
- Cool example with hiders and seeker agents. Hiders learn to push blocks into position, seekers learn to move or jump over the blocks.
- Emergent Tool Use from Multi-Agent Interaction
- Systems can actually be creative in a meaningful way
- Different from supervised learning – doesn’t just do what the data tells it to
- Requires tons of compute and “experience” – how to apply to a real world problem?
- This was the motivation for Dactyl
- Dactyl
- Training a hand to solve a Rubk’s cube
- Domain randomization
- Why can’t we train this in a simulation rather in the real world?
- Simulating friction is NP-complete
- Lots of physical factors are hard to model
- How to deal with the unknowns?
- Want to train a robust policy that can handle all of these variations.
- Automatic Domain Randomization
- ADP applied to the size of the Rubrik’s cube
- Large scale RL
- Training experience: 12,000 years
- Reorient the block and rotate the faces
- GPT-2
- Unsupervised learning by predicting the next word
- If you train a model to understand what word comes next, you should get something that understands
- Architecture of GPT-2:
- 1.5B parameter transformer
- WebText - high variety training work
- 100 Voltas for a week
- Zero-shot Question Answering
- Write down a question, and it will answer it, often correctly
- Zero-shot learning
- To summarize, just append TL;DR to a document
-
To translate French to English, do:
fr_1 = en_1] fr_2 = en_2 ... # type in: frn_n = # (and the model completes it correctly - Pretty surprising that this works, especially given that non-English sentences were stripped before training the LM.
- Popular impact
- “Talk to Transformer’
- AI Dungeon 2
- Game with Infinite Adventures
- 100 million inferences done on their NN
- Create an adventure game about literally anything
- Smart Compose for code.
AI and The Future of Humanity - Oren Etzioni
tl;dr Oren argues that while superintelligence is unlikely, it may be worth preparing for. He presents some canaries in the coalmine that would indicate superintelligence is near. TBH I would have liked to see more discussion on the real immediate risks rather than the abstract ones.
- Do we need to worry about super intelligence (AGI) yet?
- Most engineers and scientists at the conference are not concerned (by show of hands).
- But some famous scientists and engineers are . . . Stephen Hawking, Bill Gates, Elon Musk. And so is the general public.
- What would tell use if we are close to super intelligence? Maybe it is worth building up a catalog of canaries in the coal mine.
- Oren had a recent MIT TR article about this topic
- What’s in the canary catalog?
- Inflection points for AI:
- Automatic formulation of learning problems
- Approximating human common sense
- Automatic formulation of learning problems
- ML is still 99% human work!
- Inputs in ML are: Labels, Data, Algorithms.
- All which require lots of labor and engineering still.
- Inputs in ML are: Labels, Data, Algorithms.
- Codifying principles is not easy.
- First, AI should do no harm – Issac Asimov’s Laws for Robotics.
- But what is even meant by “harm”? No easy way to encode that.
- Biggest problem is trying to align what the machine is optimizing to our own “loss function” (this is hard to articulate).
- Can we learn preferences?
- Human preferences often come into conflict.
- Want to lose weight, but also eat muffins for breakfast?
- This compatibility requires dialog with humans.
- Preferences only make sense in context of commonsense knowledge
- Human preferences often come into conflict.
- Can we learn preferences?
- ML is still 99% human work!
- Approximating human common sense
- What is common sense?
- “The basic ability to perceive, understand, and judge things shared by nearly all people”
- Common facts
- Intuitive facts
- Intuitive psychology
- “The basic ability to perceive, understand, and judge things shared by nearly all people”
- Wingorad Schemas
- “The large ball crashes right through the table because it was made of steel.”
- What does “it” refer to?
- WinoGrande - Winner of AAAI 2020 Distinguished Paper Award
- “The large ball crashes right through the table because it was made of steel.”
- What is common sense?
- Inflection points for AI:
- So, should we worry about super intelligence?
- Nick Bostrom’s Meta-Algorithm
- What if we’re wrong and humanity is destroyed?
- Implication: must do everything in prepare!
- This is analogous to Pascal’s Wager (17th Century theological argument)
- You believe in God, God exists (Eternal Heaven)
- You believe in God, doesn’t exist (Nothing Happens)
- You don’t believe in God, God exists (Eternal Hell)
- You don’t believe in God, God doesn’t exist (Nothing Happens)
- The only rational thing to do is to believe in God, even if the chance is 1 in a million.
- By analogy, it is rational to prepare for superintelligence?
- Obviously, this is a reductive argument.
- What if we’re wrong and humanity is destroyed?
- Nick Bostrom’s Meta-Algorithm
- Dr. Etzioni’s “Prescription for AI”
- Identify and monitor canaries
- Address real world AI challenges with both improved technology and regulation of AI applications
- Continue to build and scale AI for the Common Good
- “Worrying about AI turning evil is a little bit like worrying about overpopulation on Mars.” — Andrew Ng
Apache Arrow: Present and Future - Wes McKinney (creator of Pandas), Ursa Labs *
tl;dr Former creator of Pandas is working on a new project to unify data processing libraries. Contribute and provide feedback if you are interested!
- About Wes: the creator of Pandas. Studied at MIT, did investment banking and started pandas, started PhD then dropped out to work on open source projects full-time.
- Covering the “boring part” of ML i.e. data processing.
- ursalabs.org - goal is to develop portable data processing libraries that can be used across many langauges
- discuss.ossdata.org - contribute to open source data processing
- Language independent open source in-memory data processing
- You should have 10X as much RAM as your dataset
Human-centric Approach to ML Infrastructure - Savin Goyal, Netflix *
tl;dr Savin developed a program called Metaflow after realizing data scientists were spending a lot of time on engineering problems outside of their core job. This was also causing the iteration cycle for product questions to be quite slow (2+ months). End result feels very similar to fblearner flow. Cool to see how this would be built with non-internal technologies.
- Michael Stonebreaker’s definition of scale: Volume, Velocity, Variety
- ETL for data (what is ETL)
- Most data scientist work ends up being engineering time — how to avoid that?
- What is the data science stack?
- Data warehouse (S3)
- Compute resources (kubernetes)
- Orchestration (Apache airflow)
- Packaging (docker)
- Metadata and versioning (git)
- Development environment (Jupyter)
- ML libraries
- Introducing “Metaflow” (metaflow.org)
- Lots of parallels to fblearner, but built by Netflix and open source.
- Supports two human activities: building and deploying data science workflows
- Building
- Arrange compute in a graph
- How to access more CPUs, GPUs or memory?
- How to version my results and access results by others?
- Deploy
- How to monitor models and examine results?
- What is the difference between Airbnb’s AirFlow vs MetaFlow?
- Airflow has a subset of the capabilities of MetaFlow. Mostly used for orchestration/scheduling.
Shipping AI Products - Panel Discussion
tl;dr Lots of parallels to Reza’s talk. Need to be mindful if ML is actually solving the product problem. Data moats are not really a thing (customers and not ML companies are owners of the data) , and labeling is a under-looked problem. Some really interesting ideas about unit testing models and adding assertions to verify correctness. If the assertion fires, then add more data until the model gets it right.
- Robert Munro (author of Human In the Loop book!), Peter Bailis (starter of DAWN project, founder of Sisu Data)
- Expectation vs reality
- Where has ML worked? Recommendation systems vs “here is the answer” — low cost of being wrong.
- Data moats — most overlooked issues. Data labeling is an afterthought. We should flip that around.
- Add “assertions” for models to make sure they are doing the right thing.
- If you me assertion fires then what do you do? Correct the label and retrain.
- Time to accuracy is also interesting and under looked problem. Want to get high accuracy quickly.
- Reinventing what accuracy means.
- Great expectations — unit testing for models.
- Papers with code (SOTA benchmarking - continuous integration for model behavior)
- Infancy of ML monitoring
- Benchmarks for models — many people don’t have them.
- Frame a problem and have an accuracy metric. Need to understand: But how does that correlate to a product metric?
- What about synthetic data?
- The most exciting use case is for rare events, rather than for general bootstrapping.
- Some classes are very robust to noisy labels, others need more accurate labels.
- Data scavenging
- If you had to give one word of advice for ML Product, what would it be?
- Understand the problem you are trying to solve, without tying the worlds ML and AI in.
- Read up on enterprise sales.
- Be obsessed with the problem, not the solution.